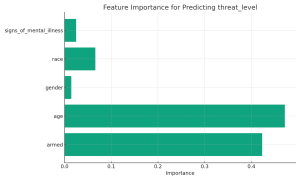
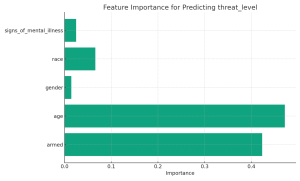
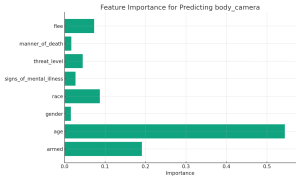
The Path to Insight through Decision Trees
In the intricate realm of criminal justice data, finding patterns in fatal police shootings is as challenging as it is crucial. A Decision Tree Classifier offers a visual and interpretable approach to machine learning, making it an excellent tool for shedding light on the factors that lead to different manners of death in such incidents.
The Rationale Behind Choosing Decision Trees
Our analytical journey led us to deploy a Decision Tree Classifier for several compelling reasons:
- Interpretability: Unlike black-box models, decision trees provide clear visualization of the decision-making process.
- Non-Linearity: Decision Trees can capture non-linear patterns, which are often present in complex datasets.
- Feature Interaction: They naturally consider the interaction between features without the need for explicit engineering.
The Analytical Process
We embarked on this path with a clear goal: to predict the ‘manner of death’ in police shootings. The dataset was pruned of any missing values, irrelevant identifiers were dropped, and categorical variables were encoded.
Upon training the Decision Tree on the cleansed dataset, it was tested for its predictive prowess.
Unveiling the Results
The Decision Tree Classifier’s performance on the test set revealed a mixed narrative:
- An impressive overall accuracy of around 90.4% was observed.
- For the majority class, presumed to be ‘not shot and Tasered’, the model scored high on all fronts—precision, recall, and F1-score each at 95%.
- For the minority class, presumed to be ‘shot and Tasered’, the model struggled with low precision and recall, both hovering around 15%.
Interpreting the Branches of Our Tree
While the Decision Tree’s high accuracy may seem promising, it is primarily indicative of its strength in predicting the majority class. The relatively low precision and recall for the minority class point to a common issue in data analytics—class imbalance—which can lead to a bias in the model’s predictions.
Recommendations for a Sturdier Tree
In pursuit of a more balanced and robust model, we propose:
- Balancing the Dataset: Employing techniques like SMOTE for the minority class to improve the model’s sensitivity to less frequent outcomes.
- Tweaking Tree Complexity: Adjusting the Decision Tree’s depth to prevent overfitting to the majority class.
- Leveraging Ensemble Methods: Combining the strengths of multiple decision trees through Random Forest or Gradient Boosting may yield a model that is both accurate and generalizable.
- Cross-validation: Implementing cross-validation techniques to ensure consistent performance across different data segments.
- Exploring Beyond the Tree: Considering other machine learning models to compare and ensure the best approach is adopted for this analysis.
Conclusion
The Decision Tree Classifier serves as a powerful starting point in the quest to understand the dynamics behind fatal police shootings. While it provides valuable insights into the data, the journey towards a model that treats all classes equitably continues. The steps we take now to refine our model will shape the tools of tomorrow, aiding in policy formulation and training that could save lives.