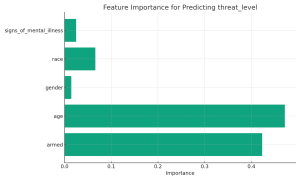
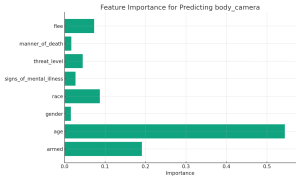
Introduction:
In an era where societal issues are under intense scrutiny, understanding the demographics of those affected by police shootings is paramount. This analysis provides a granular look into the interplay of age, race, and gender in police shootings, revealing some critical patterns and implications.
Breakdown by Age and Race:
When examining the age distribution across races:
Black Individuals: The median age was 31, with males having a right-skewed distribution around the late 20s and females around the early 30s.
Hispanic Individuals: The median age was 32 for males and 30 for females, both showing a right-skewed distribution.
White Individuals: Males had a median age of 38, while females had a median age of 39, both with a slightly right-skewed distribution.
Asian Individuals: Males had a median age of 34, while the smaller female sample had a median age of 47.
Breakdown by Race and Gender:
Males overwhelmingly dominate the dataset across all racial categories, accounting for about 95% of the total. However,
White and Black Categories: Both races had relatively higher female representations, with females accounting for approximately 5% of the total in these categories.
Other Racial Categories: Female representation was significantly smaller, due to smaller sample sizes.
Breakdown by Gender Alone:
Across all racial backgrounds:
– Males accounted for a staggering 95% of the dataset.
– Females, representing 5% of the dataset, were especially prevalent within the White (189 individuals) and Black (58 individuals) categories.
Conclusions Drawn:
1. Age Discrepancies: The age distributions indicate that Black and Hispanic individuals involved in police shootings tend to be younger. The reasons behind this trend warrant further investigation.
2. Gender Disparity: Males significantly outnumber females in all racial categories, but the presence of females, especially in the White and Black categories, is noteworthy.
3. Implications for Policy and Research: The observed patterns emphasise the importance of understanding the underlying socio-economic, geographic, and situational factors. Such insights can guide more informed policy decisions and further research endeavours.